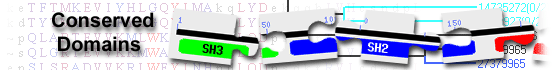Retrieve conserved domain records that contain a term(s) of interest (e.g., chloride channel). Enter the terms in the query box at the top of this page or use the Entrez Conserved Domains Database (CDD) home page. See the help document for search tips, including a list of available search fields and examples of their use.
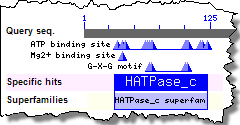
Enter a protein query as an accession or GI number (e.g., AAC50285 or 463989), or as a sequence in FASTA format, to identify the protein's conserved domains and therefore its putative function:
The Batch CD-Search tool allows the computation and download of conserved domain annotation for large sets of protein queries. Input up to 100,000 protein query sequences as a list of sequence identifiers and/or raw sequence data, then download output in a variety of formats (including tab-delimited text files) or view the search results graphically. See the help document for additional details, including information on using Batch CD-Search for scripted data downloads.
Direct fetch via UID
Retrieve a conserved domain record directly from the backend database by entering its unique identifier (UID), in the form of an accession (e.g., cd00400) or PSSM ID (e.g., 79359), in the text box below:
(Note: the "text term search" function also allows you to enter either of those unique identifiers (UIDs), but it first searches the Entrez indices for the UID, then retrieves the record. The "direct fetch via UID" option bypasses the Entrez indices and simply retrieves the specified record.)
Enter a protein query as an accession or GI number (e.g., AAC50285 or 463989), or as a sequence in FASTA format, on the Conserved Domain Architecture Retrieval Tool (CDART) page to find other proteins with similar domain architectures. (Note: If a sequence of interest is already in the Entrez Protein database, you can simply select "Domain Relatives" in that sequence record's "Links" menu to find proteins with similar architecture.)