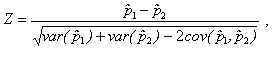![]()
| | |||||||||||
| |
|
|||||||||||
|
Results from the 2002 National Survey on Drug Use and Health (NSDUH) |
||||||||||||
An important limitation of estimates of drug use prevalence from the National Survey on Drug Use and Health (NSDUH) is that they are only designed to describe the target population of the survey—the civilian, noninstitutionalized population aged 12 or older. Although this population includes almost 98 percent of the total U.S. population aged 12 or older, it excludes some important and unique subpopulations who may have very different drug use patterns. For example, the survey excludes active military personnel, who have been shown to have significantly lower rates of illicit drug use. Persons living in institutional group quarters, such as prisons and residential drug treatment centers, are not included in NSDUH and have been shown in other surveys to have higher rates of illicit drug use. Also excluded are homeless persons not living in a shelter on the survey date, another population shown to have higher than average rates of illicit drug use. Appendix E describes other surveys that provide data for these populations.
The national estimates, along with the associated variance components, were computed using a multiprocedure package, SUrvey DAta ANalysis (SUDAAN®) Software for Statistical Analysis of Correlated Data, which was designed for the statistical analysis of sample survey data from stratified, multistage cluster samples (RTI, 2001). The final, nonresponse-adjusted, and poststratified analysis weights were used to compute unbiased design-based drug use estimates.
The sampling error (i.e., the standard error [SE]) of an estimate is the error caused by the selection of a sample instead of conducting a census of the population. Sampling error is reduced by selecting a large sample and by using efficient sample design and estimation strategies, such as stratification, optimal allocation, and ratio estimation.
With the use of probability sampling methods in NSDUH, it is possible to develop estimates of sampling error from the survey data. These estimates have been calculated in SUDAAN for all estimates presented in this report using a Taylor series linearization approach that takes into account the effects of the complex NSDUH design features. The sampling errors are used to identify unreliable estimates and to test for the statistical significance of differences between estimates.
Estimates of proportions,
![]() , such as drug use prevalence rates, take the form of nonlinear statistics where the variances cannot be expressed in closed form. Variance estimation for nonlinear statistics in SUDAAN is performed using a first-order Taylor series approximation of the deviations of estimates from their expected values.
, such as drug use prevalence rates, take the form of nonlinear statistics where the variances cannot be expressed in closed form. Variance estimation for nonlinear statistics in SUDAAN is performed using a first-order Taylor series approximation of the deviations of estimates from their expected values.
Corresponding to proportion estimates,
![]() , the number of drug users,
, the number of drug users,
![]() , can be estimated as
, can be estimated as
where ![]() is the estimated population total for domain d, and
is the estimated population total for domain d, and
![]() is the estimated proportion for domain d. The SE for the total estimate is obtained by multiplying the SE of the proportion by
is the estimated proportion for domain d. The SE for the total estimate is obtained by multiplying the SE of the proportion by
![]() , that is,
, that is,
![]() . D
. D
This approach is theoretically correct when the domain size estimates,
![]() , are among those forced to Census Bureau population projections through the weight calibration process. In these cases,
, are among those forced to Census Bureau population projections through the weight calibration process. In these cases,
![]() is clearly not subject to sampling error. For a more detailed explanation of the weight calibration process, see Section A.3.2 in Appendix A.
is clearly not subject to sampling error. For a more detailed explanation of the weight calibration process, see Section A.3.2 in Appendix A.
For domain totals,
![]() , where
, where
![]() is not fixed, this formulation may still provide a good approximation if it can be reasonably assumed that the sampling variation in
is not fixed, this formulation may still provide a good approximation if it can be reasonably assumed that the sampling variation in
![]() is negligible relative to the sampling variation in
is negligible relative to the sampling variation in
![]() . This is a reasonable assumption in most cases.
. This is a reasonable assumption in most cases.
For a subset of the tables produced from the 2002 data, it was clear that the above approach yielded an underestimate of the variance of a total because
![]() was subject to considerable variation. In these cases, a different method was used to estimate variances. SUDAAN provides an option to directly estimate the variance of the linear statistic that estimates a population total. Using this option did not affect the SE estimates for the corresponding proportions presented in the same sets of tables.
was subject to considerable variation. In these cases, a different method was used to estimate variances. SUDAAN provides an option to directly estimate the variance of the linear statistic that estimates a population total. Using this option did not affect the SE estimates for the corresponding proportions presented in the same sets of tables.
As has been done in past reports from the National Household Survey on Drug Abuse (NHSDA),1 direct survey estimates from the 2002 NSDUH considered to be unreliable due to unacceptably large sampling errors are not shown in this report and are noted by asterisks (*) in the tables containing such estimates. The criteria used for suppressing all direct survey estimates were based on the relative standard error (RSE), which is defined as the ratio of the standard error (SE) over the estimate, as well as on nominal sample size and on effective sample size. The criteria are summarized in Table B.1.
Proportion estimates (![]() ) within the range [0 <
) within the range [0 <
![]() < 1], rates, and corresponding estimated number of users were suppressed if
< 1], rates, and corresponding estimated number of users were suppressed if
or
Using a first-order Taylor series approximation to estimate
![]() and
and
![]() , the following was obtained and used for computational purposes:
, the following was obtained and used for computational purposes:
or
The separate formulas for
![]()
![]() 0.5 and
0.5 and
![]() > 0.5 produce a symmetric suppression rule (i.e., if
> 0.5 produce a symmetric suppression rule (i.e., if
![]() is suppressed, then 1 -
is suppressed, then 1 -
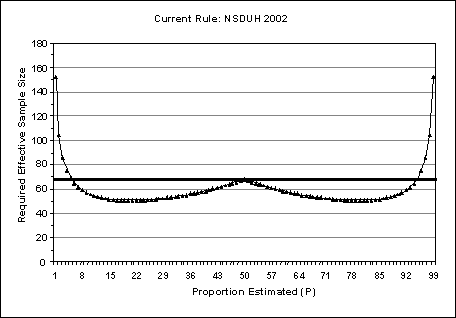
![]() will be as well). This ad hoc rule requires an effective sample size in excess of 50. When 0.05 <
will be as well). This ad hoc rule requires an effective sample size in excess of 50. When 0.05 <
![]() < 0.95, the symmetric property of the rule produces a local maximum effective sample size of 68 at
< 0.95, the symmetric property of the rule produces a local maximum effective sample size of 68 at
![]() = 0.5. Thus, estimates with these values of
= 0.5. Thus, estimates with these values of
![]() along with effective sample sizes falling below 68 are suppressed. See Figure B.1 for a graphical representation of the required minimum effective sample sizes as a function of the proportion estimated.
along with effective sample sizes falling below 68 are suppressed. See Figure B.1 for a graphical representation of the required minimum effective sample sizes as a function of the proportion estimated.
A minimum nominal sample size suppression criterion (n = 100) that protects against unreliable estimates caused by small design effects and small nominal sample sizes was employed. Prevalence estimates also were suppressed if they were close to 0 or 100 percent (i.e., if
![]() < .00005 or if
< .00005 or if
![]()
![]() .99995).
.99995).
Estimates of other totals (e.g., number of initiates) along with means and rates (both not bounded between 0 and 1) were suppressed if RSE(![]() ) > 0.5. Additionally, estimates of the mean age at first use were suppressed if the sample size was smaller than 10 respondents; moreover, the estimated incidence rate and number of initiates were suppressed if they rounded to 0.
) > 0.5. Additionally, estimates of the mean age at first use were suppressed if the sample size was smaller than 10 respondents; moreover, the estimated incidence rate and number of initiates were suppressed if they rounded to 0.
The suppression criteria for various NSDUH estimates are summarized in Table B.1 at the end of this appendix.
This section describes the methods used to compare prevalence estimates in this report. Customarily, the observed difference between estimates is evaluated in terms of its statistical significance. "Statistical significance" refers to the probability that a difference as large as that observed would occur due to random error in the estimates if there were no difference in the prevalence rates for the population groups being compared. The significance of observed differences in this report is generally reported at the 0.05 and 0.01 levels. When comparing prevalence estimates, the null hypothesis (no difference between prevalence rates) can be tested against the alternative hypothesis (there is a difference in prevalence rates) using the standard difference in proportions test expressed as follows:
where ![]() = first prevalence estimate,
= first prevalence estimate,
![]() = second prevalence estimate, var(
= second prevalence estimate, var(![]() ) = variance of first prevalence estimate, var(
) = variance of first prevalence estimate, var(![]() ) = variance of second prevalence estimate, and cov(
) = variance of second prevalence estimate, and cov(![]() ,
,
![]() ) = covariance between
) = covariance between
![]() and
and
![]() .
.
Under the null hypothesis, Z is asymptotically distributed as a normal random variable. Calculated values of Z can therefore be referred to as the unit normal distribution to determine the corresponding probability level (i.e., p value). The covariance term in the formula for Z will not always be 0. Estimates of Z, along with its p value, were calculated in SUDAAN, using the analysis weights and accounting for the sample design as described in Appendix A. A similar procedure and formula for Z were used for estimated totals.
When comparing prevalence measures between population subgroups, a χ2 test of independence of the subgroup and the prevalence variable was conducted first to control the error level for multiple comparisons. If the χ2 test indicated some significant differences, the significance of each particular subgroup comparison discussed in the report was tested using SUDAAN. Using the published estimates and standard errors to perform independent t tests for the difference of proportions will usually provide the same results as tests performed in SUDAAN. However, where the significance level is borderline, results may differ for two reasons: (1) the covariance term is included in SUDAAN tests whereas it is not included in independent t tests, and (2) the reduced number of significant digits shown in the published estimates may cause rounding errors in the independent t tests.
Nonsampling errors can occur from nonresponse, coding errors, computer processing errors, errors in the sampling frame, reporting errors, and other errors not due to sampling. Nonsampling errors are reduced through data editing, statistical adjustments for nonresponse, close monitoring and periodic retraining of interviewers, and improvement in various quality control procedures.
Although nonsampling errors can often be much larger than sampling errors, measurement of most nonsampling errors is difficult or impossible. However, some indication of the effects of some types of nonsampling errors can be obtained through proxy measures, such as response rates and from other research studies.
In 2002, response rates were improved over prior years by providing respondents with a $30 incentive. Of the 150,162 eligible households sampled for the 2002 NSDUH main study, 136,349 were successfully screened for a weighted screening response rate of 90.7 percent (Table B.2). In these screened households, a total of 80,581 sample persons were selected, and completed interviews were obtained from 68,126 of these sample persons, for a weighted interview response rate of 78.6 percent (Table B.3). A total of 7,583 (13.3 percent) sample persons were classified as refusals or parental refusals, 3,252 (4.5 percent) were not available or never at home, and 1,620 (3.7 percent) did not participate for various other reasons, such as physical or mental incompetence or language barrier (see Table B.3, which also shows the distribution of the selected sample by interview code and age group). The weighted interview response rate was highest among 12 to 17 year olds (90.0 percent), females (80.0 percent), blacks and Hispanics (82.2 and 80.9 percent, respectively), in nonmetropolitan areas (81.4 percent), and among persons residing in the Midwest (80.0 percent) (Table B.4).
The overall weighted response rate, defined as the product of the weighted screening response rate and weighted interview response rate, was 71.3 percent in 2002. Nonresponse bias can be expressed as the product of the nonresponse rate (1–R) and the difference between the characteristic of interest between respondents and nonrespondents in the population (![]() ). Thus, assuming the quantity (
). Thus, assuming the quantity (![]() ) is fixed over time, the improvement in response rates in 2002 over prior years will result in estimates with lower nonresponse bias.
) is fixed over time, the improvement in response rates in 2002 over prior years will result in estimates with lower nonresponse bias.
Among survey participants, item response rates were above 99 percent for most questionnaire items. However, inconsistent responses for some items, including the drug use items, were common. Estimates of substance use from NSDUH are based on responses to multiple questions by respondents, so that the maximum amount of information is used in determining whether a respondent is classified as a drug user. Inconsistencies in responses are resolved through a logical editing process that involves some judgment on the part of survey analysts and is a potential source of nonsampling error.
NSDUH estimates are based on self-reports of drug use, and their value depends on respondents' truthfulness and memory. Although many studies have generally established the validity of self-report data and the NSDUH procedures were designed to encourage honesty and recall, some degree of underreporting is assumed (Harrell, 1997; Harrison & Hughes, 1997; Rouse, Kozel, & Richards, 1985). No adjustment to NSDUH data is made to correct for this. The methodology used in NSDUH has been shown to produce more valid results than other self-report methods (e.g., by telephone) (Aquilino, 1994; Turner, Lessler, & Gfroerer, 1992). However, comparisons of NSDUH data with data from surveys conducted in classrooms suggest that underreporting of drug use by youths in their homes may be substantial (Gfroerer, 1993; Gfroerer, Wright, & Kopstein, 1997).
For diseases, the incidence rate for a population is defined as the number of new cases of the disease, N, divided by the person time, PT, of exposure or
![]()
The person time of exposure can be measured for the full period of the study or for a shorter period. The person time of exposure ends at the time of diagnosis (e.g., Greenberg, Daniels, Flanders, Eley, & Boring, 1996, pp. 16–19). Similar conventions are applied for defining the incidence of first use of a substance.
Beginning in 1999, the survey questionnaire allows for collection of year and month of first use for recent initiates. Month, day, and year of birth also are obtained directly or imputed in the process. In addition, the questionnaire call record provides the date of the interview. By imputing a day of first use within the year and month of first use reported or imputed, the key respondent inputs in terms of exact dates are known. Exposure time can be determined in terms of days and converted to an annual basis.
Having exact dates of birth and first use also allows the person time of exposure during the targeted period, t, to be determined. Let the target time period for measuring incidence be specified in terms of dates; for example, the period 1998 would be specified as
![]()
a period that includes 1 January 1998 and all days up to but not including 1 January 1999. The target age group also can be defined by a half-open interval as
![]() . For example, the age group 12 to 17 would be defined by
. For example, the age group 12 to 17 would be defined by
![]() for persons at least age 12, but not yet age 18. If person i was in age group a during period t, the time and age interval,
for persons at least age 12, but not yet age 18. If person i was in age group a during period t, the time and age interval,
![]() can then be determined by the intersection:
can then be determined by the intersection:
assuming the time of birth can be written in terms of day (![]() ), month (
), month (![]() ), and year (
), and year (![]() ). Either this intersection will be empty (
). Either this intersection will be empty (![]() ) or it will be designated by the half-open interval,
) or it will be designated by the half-open interval,
![]() , where
, where
![]()
and
![]()
The date of first use,
![]() , also is expressed as an exact date. An incident of first drug d use by person i in age group a occurs in time
, also is expressed as an exact date. An incident of first drug d use by person i in age group a occurs in time
![]() . The indicator function
. The indicator function
![]() used to count incidents of first use is set to 1 when
used to count incidents of first use is set to 1 when
![]() and to 0 otherwise. The person-time exposure measured in years and denoted by
and to 0 otherwise. The person-time exposure measured in years and denoted by
![]() for a person i of age group a depends on the date of first use. If the date of first use precedes the target period (
for a person i of age group a depends on the date of first use. If the date of first use precedes the target period (![]() ), then
), then
![]() . If the date of first use occurs after the target period or if person i has never used drug d, then
. If the date of first use occurs after the target period or if person i has never used drug d, then
![]()
If the date for first use occurs during the target period
![]() , then
, then
![]()
Note that both
![]() and
and
![]() are set to 0 if the target period
are set to 0 if the target period
![]() is empty (i.e., person i is not in age group a during any part of time t). The incidence rate is then estimated as a weighted ratio estimate:
is empty (i.e., person i is not in age group a during any part of time t). The incidence rate is then estimated as a weighted ratio estimate:
where the ![]() are the analytic weights.
are the analytic weights.
Starting in 2002, estimates were reported separately for males and females, as well as overall. These estimates only use data from the 2002 survey because 2002 estimates provide a new baseline for measuring change. Therefore, even though the methodology between 1999–2001 and 2002 is the same, the estimates are not comparable. For a more detailed explanation of the incidence methodology, see Packer, Odom, Chromy, Davis, and Gfroerer (2002). The estimates in this report are based on retrospective reports of age at first drug use by survey respondents interviewed during 2002. Because they are based on retrospective reports as was the case for earlier estimates, they may be subject to some of the same kinds of biases.
Bias due to differential mortality occurs because some persons who were alive and exposed to the risk of first drug use in the historical periods shown in the tables died before the 2002 NSDUH was conducted. This bias is probably very small for estimates shown in this report. Incidence estimates also are affected by memory errors, including recall decay (tendency to forget events occurring long ago) and forward telescoping (tendency to report that an event occurred more recently than it actually did). These memory errors would both tend to result in estimates for earlier years (i.e., 1960s and 1970s) that are downwardly biased (because of recall decay) and estimates for later years that are upwardly biased (because of telescoping). There also is likely to be some underreporting bias due to social acceptability of drug use behaviors and respondents' fear of disclosure. This is likely to have the greatest impact on recent estimates, which reflect more recent use and reporting by younger respondents. Finally, for drug use that is frequently initiated at age 10 or younger, estimates based on retrospective reports 1 year later underestimate total incidence because 11–year–old (and younger) children are not sampled by NSDUH. Prior analyses showed that alcohol and cigarette (any use) incidence estimates could be significantly affected by this. Therefore, for these drugs, only 2001 age-specific rates and the number of initiates 18 or older were reported.
Retrospective measures of lifetime substance use prevalence were obtained for prior years based on the 2002 sample. Lifetime prevalence measures are defined as of a specified date as the ratio
![]()
where the numerator,![]() , represents all persons who report lifetime use as of that date and the numerator,
, represents all persons who report lifetime use as of that date and the numerator,![]() , represents both lifetime users and nonusers. For NSDUH current year estimates, the specified date is the date of interview for each respondent.
, represents both lifetime users and nonusers. For NSDUH current year estimates, the specified date is the date of interview for each respondent.
As was described in Section B.4, complete data on a respondent's exact date of first substance use is known or imputed during the processing of the current year's data. In addition, the date of interview and date of birth are on the current year's data file. These data make it possible to retrospectively estimate lifetime prevalence measures for prior years based on the current year respondents.
Because comparisons of prevalence rates across years from this analysis are based on a common sample, the precision of trend estimates is improved. On the negative side, the retrospective measures do not properly reflect the impacts of migration and mortality.2 To control for the possible effects of mortality, the retrospective estimates are limited to the younger age groups: 12 to 17 and 18 to 25. In addition, retrospective prevalence estimates may be biased due to memory errors. As noted in the discussion of incidence estimates (Section B.4), recall decay leads to a general downward bias. Forward telescoping (the tendency to report initial substance use more recently than it actually occurred) will create downward bias in early years, but have little impact on recent estimates. It also should be noted that due to the sampling strategy that selects older persons with lower probabilities of selection, the estimates for early years (reported by persons who are now 26 or older) are based on much smaller sample sizes and subject to more sampling error.
A key assumption for computing retrospective lifetime prevalence estimates is that the month and day of the respondent use and age status in prior years is based on the same month and day as the date of interview in the current survey year. Retrospective estimates, PR(d,a,t), of lifetime substance d use were prepared for 1965 to 2002 as a simple ratio estimate for year t and age group a as:
where ![]() is the respondent's analytic weight for 2002. The values of
is the respondent's analytic weight for 2002. The values of
![]() and
and
![]() are determined from
are determined from
For the current survey year,
![]() has a value of 1 if the current age of respondent i is in the interval a, and a value of 0 otherwise. If the age interval is 12 to 17, then the respondent must be at least 12, but not yet 18. For the current survey year,
has a value of 1 if the current age of respondent i is in the interval a, and a value of 0 otherwise. If the age interval is 12 to 17, then the respondent must be at least 12, but not yet 18. For the current survey year,
![]() has a value of 1 if
has a value of 1 if
![]() has a value of 1 and respondent i is a lifetime user of substance d. For current lifetime users, this means that their reported date of first use is on or before the date of interview (i.e., if
has a value of 1 and respondent i is a lifetime user of substance d. For current lifetime users, this means that their reported date of first use is on or before the date of interview (i.e., if
![]() ). Otherwise,
). Otherwise,
![]() has a value of 0.
has a value of 0.
For prior years, it is first necessary to compute the difference in the years as
![]() . Then,
. Then,
![]() has a value of 1 if respondent i retrospectively adjusted age,
has a value of 1 if respondent i retrospectively adjusted age,
![]() is in the interval a, and a value of 0 otherwise. Also,
is in the interval a, and a value of 0 otherwise. Also,
![]() has a value of 1 if
has a value of 1 if
![]() has a value of 1, respondent i is a lifetime user of substance d, and the reported date of first use is on or before an adjusted date of interview (i.e., if
has a value of 1, respondent i is a lifetime user of substance d, and the reported date of first use is on or before an adjusted date of interview (i.e., if
![]() ). Otherwise,
). Otherwise,
![]() has a value of 0.
has a value of 0.
For the 2002 survey, mental health among adults was measured using a scale to ascertain serious mental illness (SMI). This scale consisted of six questions that ask respondents how frequently they experienced symptoms of psychological distress during the 1 month in the past year when they were at their worst emotionally. The use of this scale is based on a methodological study designed to evaluate several screening scales for measuring SMI in NSDUH. These scales consisted of a truncated version of the World Health Organization (WHO) Composite International Diagnostic Interview Short Form (CIDI-SF) scale (Kessler, Andrews, Mroczek, Üstün, & Wittchen, 1998), the K10/K6 scale of nonspecific psychological distress (Furukawa, Kessler, Slade, & Andrews, 2003), and the WHO Disability Assessment Schedule (WHO-DAS) (Rehm et al., 1999).
The methodological study to evaluate the scales consisted of 155 respondents selected from a first-stage sample of 1,000 adults aged 18 or older. First-stage respondents were selected from the Boston metropolitan area and screened on the telephone to determine whether they had any emotional problems. Respondents reporting emotional problems at the first stage were oversampled when selecting the 155 respondents at the second stage. The selected respondents were interviewed by trained clinicians in respondents' homes using both the NSDUH methodology and a structured clinical interview. The first interview included the three scales described above using audio computer-assisted self-interviewing (ACASI). Respondents completed the ACASI portion of the interview without discussing their answers with the clinician. After completing the ACASI interview, respondents then were interviewed using the 12–month nonpatient version of the Structured Clinical Interview for DSM-IV (SCID) (First, Spitzer, Gibbon, & Williams, 1997) and the Global Assessment of Functioning (GAF) (Endicott, Spitzer, Fleiss, & Cohen, 1976) to classify respondents as either having or not having SMI.
The data from the 155 respondents were analyzed using logistic regression analysis to predict SMI from the scores on the screening questions. Analysis of the model fit indicated that each of the scales alone and in combination were significant predictors of SMI and the best fitting models contained either the CIDI-SF or the K10/K6 alone. Receiver operating characteristic (ROC) curve analysis was used to evaluate the precision of the scales to discriminate between respondents with and without SMI. This analysis indicated that the K6 was the best predictor. The results of the methodological study are described in more detail in a paper describing the K10/K6 scale of nonspecific psychological distress (Kessler et al., 2003).
To score the items on the K6 scales, they were first coded from 0 to 4 and summed to yield a number between 0 and 24. This involved transforming response categories for the six questions (DSNERV1, DSHOPE, DSFIDG, DSNOCHR, DSEFFORT, and DSDOWN) given below so that "all of the time" is coded 4, "most of the time" is coded 3, "some of the time" 2, "a little of the time" 1, and "none of the time" 0, with "don't know" and "refuse" also coded 0. Summing across the transformed responses results in a score with a range from 0 to 24. Respondents with a total score of 13 or greater were classified as having a past year SMI. This cutpoint was chosen to equalize false positives and false negatives.
The questions comprising the K6 scale are given as follows:
During that month, how often did you feel nervous?
1 All of the time
2 Most of the time
3 Some of the time
4 A little of the time
5 None of the time
DK/REF
Response categories are the same for the following questions:
Table B.1 Summary of 2002 NSDUH Suppression Rules
| Estimate | Suppress if: |
|---|---|
| Prevalence rate, |
The estimated prevalence rate,
Effective n<68, or n<100, where
Note: The rounding portion of this suppression rule for prevalence rates will produce some estimates that round at one decimal place to 0.0 or 100.0 percent but are not suppressed from the tables. |
| Estimated number (numerator of |
The estimated prevalence rate,
Note: In some instances when
|
| Mean age at first use,
|
n>10. |
| Incidence rate,
|
Rounds to < 0.1 per 1,000 person-years of exposure, or
|
| Number of initiates,
|
Rounds to < 1,000 initiates, or
|
Source: SAMHSA, Office of Applied Studies, National Survey on Drug Use and Health, 2002.
Table B.2 Weighted Percentages and Sample Sizes for 2002 NSDUH, by Screening Result Code
| Screening Result | 2002 NSDUH | |
|---|---|---|
| Sample Size |
Weighted Percentage |
|
| Total Sample | 178,013 | 100.00 |
| Ineligible cases | 27,851 | 15.27 |
| Eligible cases | 150,162 | 84.73 |
| Ineligibles | 27,851 | 15.27 |
| Vacant | 14,417 | 51.55 |
| Not a primary residence | 4,580 | 17.36 |
| Not a dwelling unit | 2,403 | 8.16 |
| Resident < 1/2 of quarter | 0 | 0.00 |
| All military personnel | 289 | 1.08 |
| Other, ineligible | 6,162 | 21.86 |
| Eligible Cases | 150,162 | 84.73 |
| Screening complete | 136,349 | 90.72 |
| No one selected | 80,557 | 53.14 |
| One selected | 30,738 | 20.58 |
| Two selected | 25,054 | 17.00 |
| Screening not complete | 13,813 | 9.28 |
| No one home | 3,031 | 2.02 |
| Respondent unavailable | 411 | 0.26 |
| Physically or mentally incompetent | 307 | 0.20 |
| Language barrier—Hispanic | 66 | 0.05 |
| Language barrier—other | 461 | 0.35 |
| Refusal | 8,556 | 5.86 |
| Other, access denied | 471 | 0.30 |
| Other, eligible | 12 | 0.01 |
| Segment not accessible | 0 | 0.00 |
| Screener not returned | 15 | 0.01 |
| Fraudulent case | 479 | 0.21 |
| Electronic screening problem | 4 | 0.00 |
Source: SAMHSA, Office of Applied Studies, National Survey on Drug Use and Health, 2002.
Table B.3 Weighted Percentages and Sample Sizes for 2002 NSDUH, by Final Interview Code
| Final Interview Code | Persons Aged 12 or Older |
Persons Aged 12–17 |
Persons Aged 18 or Older |
|||
|---|---|---|---|---|---|---|
| Sample Size |
Weighted Percentage |
Sample Size |
Weighted Percentage |
Sample Size |
Weighted Percentage |
|
| Total | 80,581 | 100.00 | 26,230 | 100.00 | 54,351 | 100.00 |
| Interview Complete | 68,126 | 78.56 | 23,659 | 89.99 | 44,467 | 77.20 |
| No One at Dwelling Unit | 1,359 | 1.81 | 182 | 0.70 | 1,177 | 1.94 |
| Respondent Unavailable | 1,893 | 2.71 | 329 | 1.20 | 1,564 | 2.89 |
| Break-Off | 48 | 0.10 | 9 | 0.04 | 39 | 0.11 |
| Physically/Mentally Incompetent | 692 | 1.75 | 161 | 0.57 | 531 | 1.89 |
| Language barrier—Spanish | 138 | 0.19 | 9 | 0.04 | 129 | 0.21 |
| Language barrier—Other | 327 | 1.09 | 24 | 0.13 | 303 | 1.21 |
| Refusal | 6,276 | 12.73 | 464 | 1.81 | 5,812 | 14.03 |
| Parental Refusal | 1,307 | 0.55 | 1,307 | 5.15 | 0 | 0.00 |
| Other | 415 | 0.52 | 86 | 0.38 | 329 | 0.53 |
Source: SAMHSA, Office of Applied Studies, National Survey on Drug Use and Health, 2002.
Table B.4 Response Rates and Sample Sizes for 2002 NSDUH, by Demographic Characteristics
| 2002 NSDUH | |||
|---|---|---|---|
| Selected Persons |
Completed Interviews |
Weighted Response Rate |
|
| Total | 80,581 | 68,126 | 78.56% |
| Age in Years | |||
| 12–17 | 26,230 | 23,659 | 89.99% |
| 18–25 | 27,216 | 23,271 | 85.16% |
| 26 or older | 27,135 | 21,196 | 75.81% |
| Gender | |||
| Male | 39,453 | 32,766 | 77.06% |
| Female | 41,128 | 35,360 | 79.99% |
| Race/Ethnicity | |||
| Hispanic | 10,250 | 8,692 | 80.93% |
| White | 55,594 | 46,834 | 78.23% |
| Black | 9,385 | 8,143 | 82.24% |
| All other races | 5,352 | 4,457 | 70.50% |
| Region | |||
| Northeast | 16,490 | 13,706 | 75.57% |
| Midwest | 22,588 | 19,180 | 80.01% |
| South | 24,530 | 20,900 | 79.99% |
| West | 16,973 | 14,340 | 77.33% |
| County Type | |||
| Large metropolitan | 32,294 | 26,792 | 76.85% |
| Small metropolitan | 28,121 | 23,944 | 79.50% |
| Nonmetropolitan | 20,166 | 17,390 | 81.38% |
Source: SAMHSA, Office of Applied Studies, National Survey on Drug Use and Health, 2002.
1 Beginning with the 2002 survey year, the survey name was changed from the National Household Survey on Drug Abuse (NHSDA) to the National Survey on Drug Use and Health (NSDUH).
2 The same limitations apply to the estimates of incidence rates for prior years based on the current sample responses.
![]()

This page was last updated on June 03, 2008. |
|
SAMHSA, an agency in the Department of Health and Human Services, is the Federal Government's lead agency for improving the quality and availability of substance abuse prevention, addiction treatment, and mental health services in the United States.
* PDF formatted files require that Adobe Acrobat Reader® program is installed on your computer. Click here to download this FREE software now from Adobe. |